Java集合(十一): LinkedHashMap远源码剖析
写在前面
HashMap和双向链表合二为一即是LinkedHashMap。
LinkedHashMap,其落脚点在HashMap,因此更准确地说,它是一个将所有Entry节点链入一个双向链表的HashMap。由于LinkedHashMap是HashMap的子类,所以LinkedHashMap自然会拥有HashMap的所有特性。比如,LinkedHashMap的元素存取过程基本与HashMap基本类似,只是在细节实现上稍有不同。
当然,这是由LinkedHashMap本身的特性所决定的,因为它额外维护了一个双向链表用于保持迭代顺序。此外,LinkedHashMap可以很好的支持LRU算法。
1、LinkedHashMap 简介
HashMap是无序的,迭代HashMap所得到的元素顺序并不是它们最初放置到HashMap的顺序。HashMap的这一缺点往往会造成诸多不便,因为在有些场景中,我们确需要用到一个可以保持插入顺序的Map。
LinkedHashMap。虽然LinkedHashMap增加了时间和空间上的开销,但是它通过维护一个额外的双向链表保证了迭代顺序。特别地,该迭代顺序可以是插入顺序,也可以是访问顺序。因此,根据链表中元素的顺序可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap 和 保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的。
2、LinkedHashMap数据结构
下图很好地还原了LinkedHashMap的原貌:HashMap和双向链表的密切配合和分工合作造就了LinkedHashMap。next用于维护HashMap各个桶中的Entry链,before、after用于维护LinkedHashMap的双向链表,虽然它们的作用对象都是Entry,但是各自分离,是两码事儿。
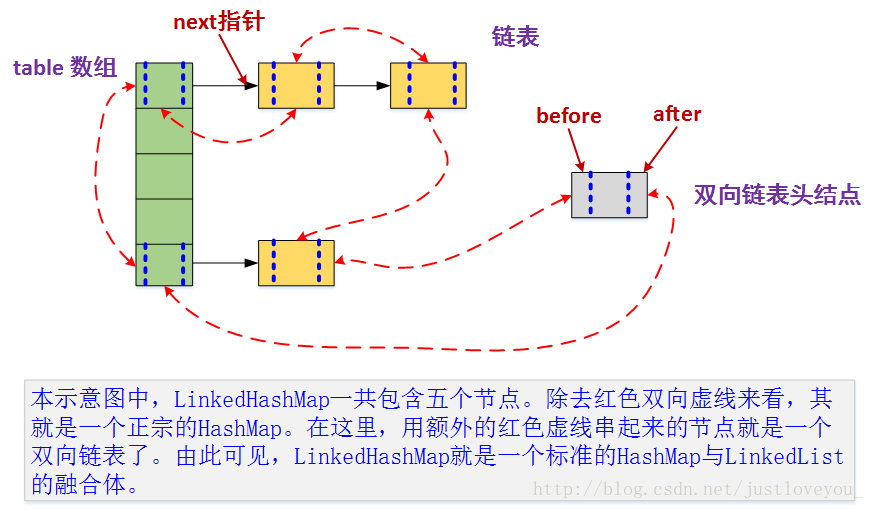

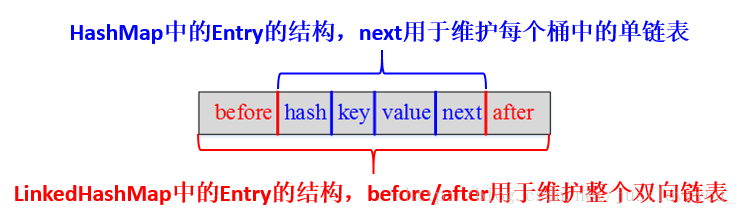
其中,HashMap与LinkedHashMap的Entry结构示意图如下图所示:
3、LinkedHashMap源码分析
3.1、LinkedHashMap继承结构和层次关系
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
...
}
3.2、成员变量
与HashMap相比,LinkedHashMap增加了两个属性用于保证迭代顺序,分别是 双向链表头结点header 和 标志位accessOrder (值为true时,表示按照访问顺序迭代;值为false时,表示按照插入顺序迭代)。** **
// 双向链表的表头元素
private transient Entry<K,V> header;
//true表示按照访问顺序迭代,false时表示按照插入顺序
private final boolean accessOrder; 3.3、成员方法定义
从下图我们可以看出,LinkedHashMap中并增加没有额外方法。也就是说,LinkedHashMap与HashMap在操作上大致相同,只是在实现细节上略有不同罢了。

3.4、基本元素 Entry
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了Entry。 LinkedHashMap中的Entry增加了两个指针 before 和 after,它们分别用于维护双向链接列表特别需要注意的是,next用于维护HashMap各个桶中Entry的连接顺序,before、after用于维护Entry插入的先后顺序的。
在HashMap存储 key-value 的类为Node(属性主要包括hash、key、value),
在LinkedHashMap类用于要记录Linked状态,所以增加一个继承Node的内部类Entry。Entry类只是增加before、after指针而已,在LinkedHashMap用Entry对象存key-value。
源代码如下:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}形象地,HashMap与LinkedHashMap的Entry结构示意图如下图所示:
4、LinkedHashMap 的构造函数
LinkedHashMap 一共提供了五个构造函数,它们都是在HashMap的构造函数的基础上实现的,分别如下:
1、LinkedHashMap()
构造一个具有 默认初始容量 (16)和默认负载因子(0.75)的空 LinkedHashMap。
public LinkedHashMap() {
super(); // 调用HashMap对应的构造函数
accessOrder = false; // 迭代顺序的默认值
}2、LinkedHashMap(int initialCapacity, float loadFactor)
该构造函数意在构造一个指定初始容量和指定负载因子的空 LinkedHashMap。
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor); // 调用HashMap对应的构造函数
accessOrder = false; // 迭代顺序的默认值
}3、LinkedHashMap(int initialCapacity)
该构造函数意在构造一个指定初始容量和默认负载因子 (0.75)的空 LinkedHashMap。
public LinkedHashMap(int initialCapacity) {
super(initialCapacity); // 调用HashMap对应的构造函数
accessOrder = false; // 迭代顺序的默认值
}4、LinkedHashMap(Map<? extends K, ? extends V> m)
该构造函数意在构造一个与指定 Map 具有相同映射的 LinkedHashMap,其初始容量不小于 16 (具体依赖于指定Map的大小),负载因子是 0.75。
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m); // 调用HashMap对应的构造函数
accessOrder = false; // 迭代顺序的默认值
}5、LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
该构造函数意在构造一个指定初始容量和指定负载因子的具有指定迭代顺序的LinkedHashMap
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor); // 调用HashMap对应的构造函数
this.accessOrder = accessOrder; // 迭代顺序的默认值
}6、init 方法
从上面的五种构造函数我们可以看出,无论采用何种方式创建LinkedHashMap,其都会调用HashMap相应的构造函数。事实上,不管调用HashMap的哪个构造函数,HashMap的构造函数都会在最后调用一个init()方法进行初始化,只不过这个方法在HashMap中是一个空实现,而在LinkedHashMap中重写了它用于初始化它所维护的双向链表。
例如,HashMap的参数为空的构造函数以及init方法的源码如下:
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
void init() {
}在LinkedHashMap中,它重写了init方法以便初始化双向列表,源码如下:
void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
}因此,我们在创建LinkedHashMap的同时就会不知不觉地对双向链表进行初始化。
参考:史上最详细的 JDK 1.8 HashMap 源码解析_程序员囧辉-CSDN博客_hashmap详解Map 综述(二):彻头彻尾理解 LinkedHashMap_Rico's Blogs-CSDN博客_linkedhashmap
超详细LinkedHashMap解析_求offer的菜鸡的博客-CSDN博客_linkedhashmap
版权说明 : 本文为转载文章, 版权归原作者所有 版权申明
原文链接 : https://blog.csdn.net/mingyuli/article/details/120701174
内容来源于网络,如有侵权,请联系作者删除!
相关文章
热门标签
更多最新文章
更多- 浏览(814) 发布于 6个月前
- 浏览(306) 发布于 6个月前
- 浏览(304) 发布于 6个月前
- 浏览(302) 发布于 6个月前
- 浏览(305) 发布于 6个月前