CNN笔记:通俗理解卷积神经网络
通俗理解卷积神经网络(cs231n与5月dl班课程笔记)
1 前言
2012年我在北京组织过8期machine learning读书会,那时“机器学习”非常火,很多人都对其抱有巨大的热情。当我2013年再次来到北京时,有一个词似乎比“机器学习”更火,那就是“深度学习”。
本博客内写过一些机器学习相关的文章,但上一篇技术文章“LDA主题模型”还是写于2014年11月份,毕竟自2015年开始创业做在线教育后,太多的杂事、琐碎事,让我一直想再写点技术性文章但每每恨时间抽不开。然由于公司在不断开机器学习、深度学习等相关的在线课程,耳濡目染中,总会顺带着学习学习。
我虽不参与讲任何课程(我所在公司“七月在线”的所有在线课程都是由目前讲师团队的数百位讲师讲),但依然可以用最最小白的方式 把一些初看复杂的东西抽丝剥茧的通俗写出来。这算重写技术博客的价值所在。
在dl中,有一个很重要的概念,就是卷积神经网络CNN,基本是入门dl必须搞懂的东西。本文基本根据斯坦福的机器学习公开课、cs231n、与七月在线寒老师讲的5月dl班所写,是一篇课程笔记。
一开始本文只是想重点讲下CNN中的卷积操作具体是怎么计算怎么操作的,但后面不断补充,包括增加不少自己的理解,故写成了关于卷积神经网络的通俗导论性的文章。有何问题,欢迎不吝指正。
2 人工神经网络
2.1 神经元
神经网络由大量的神经元相互连接而成。每个神经元接受线性组合的输入后,最开始只是简单的线性加权,后来给每个神经元加上了非线性的激活函数,从而进行非线性变换后输出。每两个神经元之间的连接代表加权值,称之为权重(weight)。不同的权重和激活函数,则会导致神经网络不同的输出。
举个手写识别的例子,给定一个未知数字,让神经网络识别是什么数字。此时的神经网络的输入由一组被输入图像的像素所激活的输入神经元所定义。在通过非线性激活函数进行非线性变换后,神经元被激活然后被传递到其他神经元。重复这一过程,直到最后一个输出神经元被激活。从而识别当前数字是什么字。
神经网络的每个神经元如下
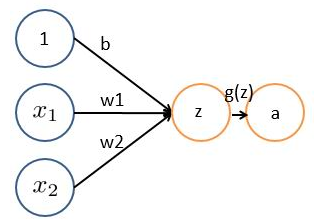
基本wx + b的形式,其中
、
表示输入向量
*
、
为权重,几个输入则意味着有几个权重,即每个输入都被赋予一个权重
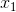
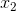
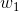
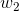
- b为偏置bias
- g(z) 为激活函数
- a 为输出
如果只是上面这样一说,估计以前没接触过的十有八九又必定迷糊了。事实上,上述简单模型可以追溯到20世纪50/60年代的感知器,可以把感知器理解为一个根据不同因素、以及各个因素的重要性程度而做决策的模型。
举个例子,这周末北京有一草莓音乐节,那去不去呢?决定你是否去有二个因素,这二个因素可以对应二个输入,分别用x1、x2表示。此外,这二个因素对做决策的影响程度不一样,各自的影响程度用权重w1、w2表示。一般来说,音乐节的演唱嘉宾会非常影响你去不去,唱得好的前提下 即便没人陪同都可忍受,但如果唱得不好还不如你上台唱呢。所以,我们可以如下表示:
:是否有喜欢的演唱嘉宾。
= 1 你喜欢这些嘉宾,
= 0 你不喜欢这些嘉宾。嘉宾因素的权重
= 7
*
:是否有人陪你同去。
= 1 有人陪你同去,
= 0 没人陪你同去。是否有人陪同的权重
= 3。
这样,咱们的决策模型便建立起来了:g(z) = g(
*
+
*
- b ),g表示激活函数,这里的b可以理解成 为更好达到目标而做调整的偏置项。
一开始为了简单,人们把激活函数定义成一个线性函数,即对于结果做一个线性变化,比如一个简单的线性激活函数是g(z) = z,输出都是输入的线性变换。后来实际应用中发现,线性激活函数太过局限,于是人们引入了非线性激活函数。
2.2 激活函数
常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者relu常见于卷积层。这里先简要介绍下最基础的sigmoid函数(btw,在本博客中SVM那篇文章开头有提过)。
sigmoid的函数表达式如下
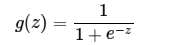
其中z是一个线性组合,比如z可以等于:b +
*
+
*
。通过代入很大的正数或很小的负数到g(z)函数中可知,其结果趋近于0或1。
因此,sigmoid函数g(z)的图形表示如下( 横轴表示定义域z,纵轴表示值域g(z) ):
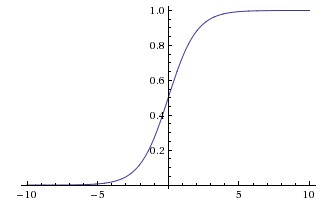
也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常小的负数时,则g(z)会趋近于0。
压缩至0到1有何用处呢?用处是这样一来便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
举个例子,如下图(图引自Stanford机器学习公开课)

z = b +
*
+
*
,其中b为偏置项 假定取-30,
、
都取为20
- 如果
= 0
= 0,则z = -30,g(z) = 1/( 1 + e^-z )趋近于0。此外,从上图sigmoid函数的图形上也可以看出,当z=-30的时候,g(z)的值趋近于0 - 如果
= 0
= 1,或
=1
= 0,则z = b +
+
*
= -30 + 20 = -10,同样,g(z)的值趋近于0
- 如果
= 1
= 1,则z = b +
+
*
= -30 + 201 + 201 = 10,此时,g(z)趋近于1。
换言之,只有
和
都取1的时候,g(z)→1,判定为正样本;
或
取0的时候,g(z)→0,判定为负样本,如此达到分类的目的。
2.3 神经网络
将下图的这种单个神经元
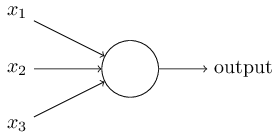
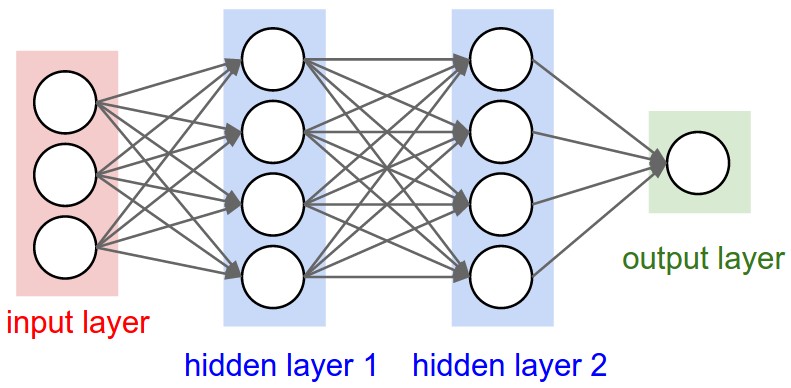
组织在一起,便形成了神经网络。下图便是一个三层神经网络结构
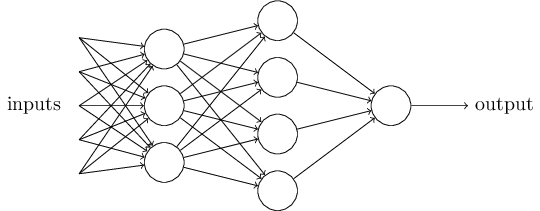
上图中最左边的原始输入信息称之为输入层,最右边的神经元称之为输出层(上图中输出层只有一个神经元),中间的叫隐藏层。
啥叫输入层、输出层、隐藏层呢?
- 输入层(Input layer),众多神经元(Neuron)接受大量非线形输入讯息。输入的讯息称为输入向量。
- 输出层(Output layer),讯息在神经元链接中传输、分析、权衡,形成输出结果。输出的讯息称为输出向量。
- 隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。如果有多个隐藏层,则意味着多个激活函数。
同时,每一层都可能由单个或多个神经元组成,每一层的输出将会作为下一层的输入数据。比如下图中间隐藏层来说,隐藏层的3个神经元a1、a2、a3皆各自接受来自多个不同权重的输入(因为有x1、x2、x3这三个输入,所以a1 a2 a3都会接受x1 x2 x3各自分别赋予的权重,即几个输入则几个权重),接着,a1、a2、a3又在自身各自不同权重的影响下 成为的输出层的输入,最终由输出层输出最终结果。
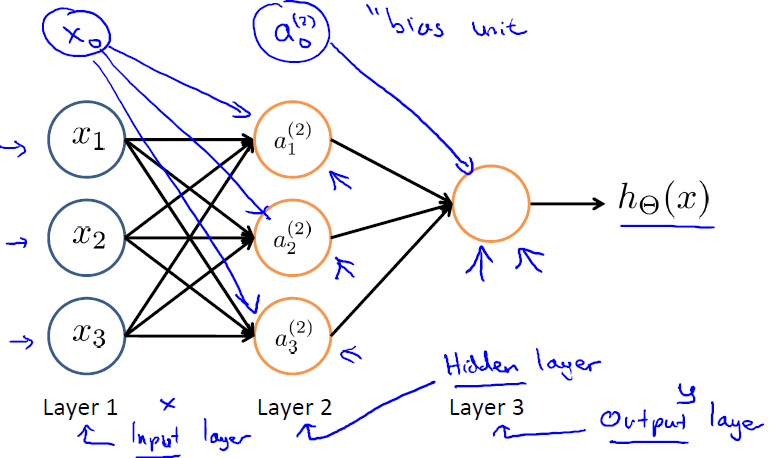
上图(图引自Stanford机器学习公开课)中
表示第j层第i个单元的激活函数/神经元
*
表示从第j层映射到第j+1层的控制函数的权重矩阵
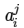
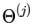
此外,输入层和隐藏层都存在一个偏置(bias unit),所以上图中也增加了偏置项:x0、a0。针对上图,有如下公式
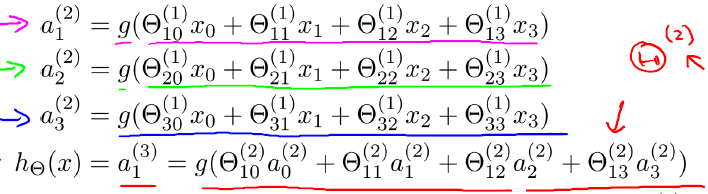
此外,上文中讲的都是一层隐藏层,但实际中也有多层隐藏层的,即输入层和输出层中间夹着数层隐藏层,层和层之间是全连接的结构,同一层的神经元之间没有连接。
3 卷积神经网络之层级结构
cs231n课程里给出了卷积神经网络各个层级结构,如下图
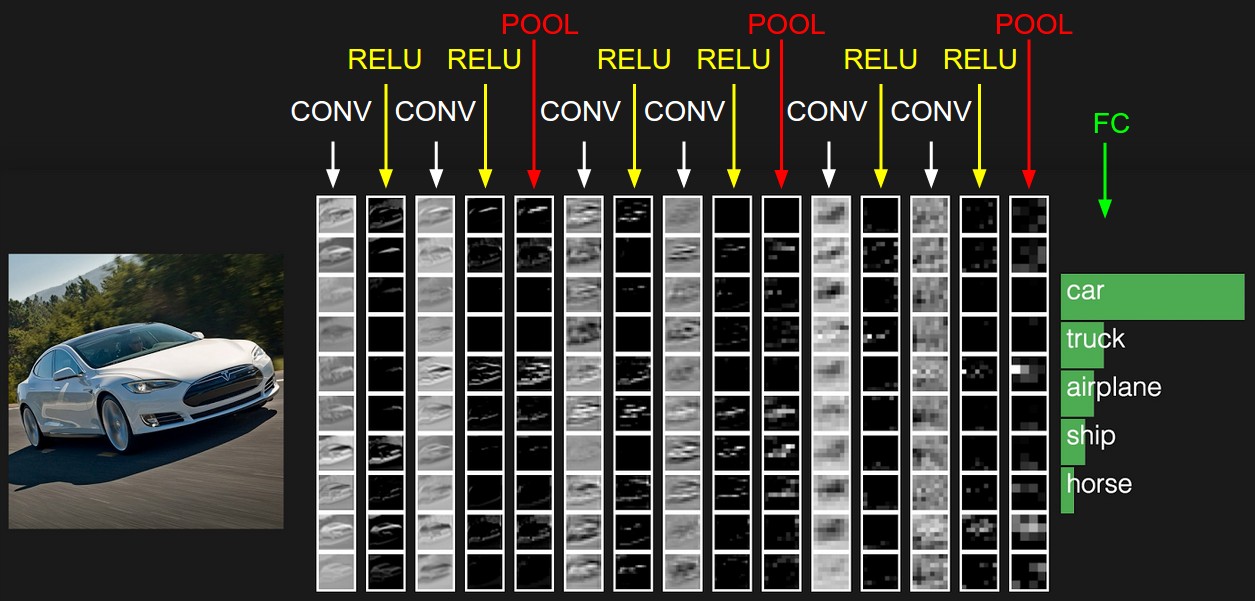
上图中CNN要做的事情是:给定一张图片,是车还是马未知,是什么车也未知,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是车 那是什么车
所以
- 最左边是数据输入层,对数据做一些处理,比如去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA/白化等等。CNN只对训练集做“去均值”这一步。
中间是
- CONV:卷积计算层,线性乘积 求和。
- RELU:激励层,上文2.2节中有提到:ReLU是激活函数的一种。
- POOL:池化层,简言之,即取区域平均或最大。
最右边是
- FC:全连接层
这几个部分中,卷积计算层是CNN的核心,下文将重点阐述。
4 CNN之卷积计算层
4.1 CNN怎么进行识别
简言之,当我们给定一个"X"的图案,计算机怎么识别这个图案就是“X”呢?一个可能的办法就是计算机存储一张标准的“X”图案,然后把需要识别的未知图案跟标准"X"图案进行比对,如果二者一致,则判定未知图案即是一个"X"图案。
而且即便未知图案可能有一些平移或稍稍变形,依然能辨别出它是一个X图案。如此,CNN是把未知图案和标准X图案一个局部一个局部的对比,如下图所示 [图来自参考文案25]

而未知图案的局部和标准X图案的局部一个一个比对时的计算过程,便是卷积操作。卷积计算结果为1表示匹配,否则不匹配。
具体而言,为了确定一幅图像是包含有"X"还是"O",相当于我们需要判断它是否含有"X"或者"O",并且假设必须两者选其一,不是"X"就是"O"。

理想的情况就像下面这个样子:

标准的"X"和"O",字母位于图像的正中央,并且比例合适,无变形
对于计算机来说,只要图像稍稍有一点变化,不是标准的,那么要解决这个问题还是不是那么容易的:

计算机要解决上面这个问题,一个比较天真的做法就是先保存一张"X"和"O"的标准图像(就像前面给出的例子),然后将其他的新给出的图像来和这两张标准图像进行对比,看看到底和哪一张图更匹配,就判断为哪个字母。
但是这么做的话,其实是非常不可靠的,因为计算机还是比较死板的。在计算机的“视觉”中,一幅图看起来就像是一个二维的像素数组(可以想象成一个棋盘),每一个位置对应一个数字。在我们这个例子当中,像素值"1"代表白色,像素值"-1"代表黑色。

当比较两幅图的时候,如果有任何一个像素值不匹配,那么这两幅图就不匹配,至少对于计算机来说是这样的。
对于这个例子,计算机认为上述两幅图中的白色像素除了中间的3*3的小方格里面是相同的,其他四个角上都不同:

因此,从表面上看,计算机判别右边那幅图不是"X",两幅图不同,得出结论:

但是这么做,显得太不合理了。理想的情况下,我们希望,对于那些仅仅只是做了一些像平移,缩放,旋转,微变形等简单变换的图像,计算机仍然能够识别出图中的"X"和"O"。就像下面这些情况,我们希望计算机依然能够很快并且很准的识别出来:

这也就是CNN出现所要解决的问题。
Features

对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征)。在两幅图中大致相同的位置找到一些粗糙的特征进行匹配,CNN能够更好的看到两幅图的相似性,相比起传统的整幅图逐一比对的方法。
每一个feature就像是一个小图(就是一个比较小的有值的二维数组)。不同的Feature匹配图像中不同的特征。在字母"X"的例子中,那些由对角线和交叉线组成的features基本上能够识别出大多数"X"所具有的重要特征。

这些features很有可能就是匹配任何含有字母"X"的图中字母X的四个角和它的中心。那么具体到底是怎么匹配的呢?如下:





看到这里是不是有了一点头目呢。但其实这只是第一步,你知道了这些Features是怎么在原图上面进行匹配的。但是你还不知道在这里面究竟进行的是怎样的数学计算,比如这个下面3*3的小块到底干了什么?

这里面的数学操作,就是我们常说的“卷积”操作。接下来,我们来了解下什么是卷积操作。
4.2 什么是卷积
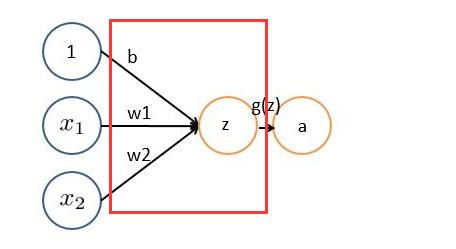
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
非严格意义上来讲,下图中红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层。
OK,举个具体的例子。比如下图中,图中左边部分是原始输入数据,图中中间部分是滤波器filter,图中右边是输出的新的二维数据。
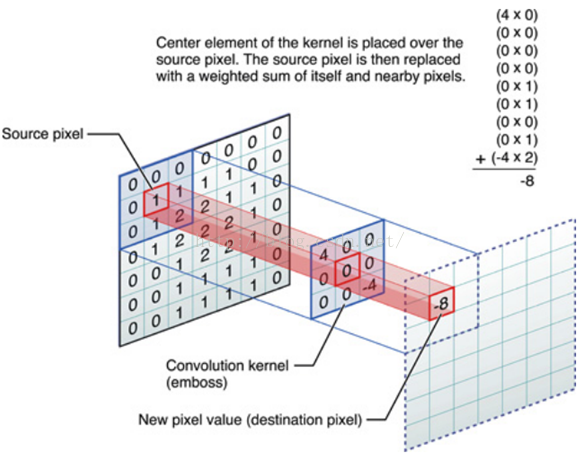
分解下上图
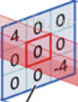
对应位置上是数字先相乘后相加
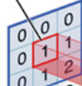

中间滤波器filter与数据窗口做内积,其具体计算过程则是:40 + 00 + 00 + 00 + 01 + 01 + 00 + 01 + -4*2 = -8
4.3 图像上的卷积
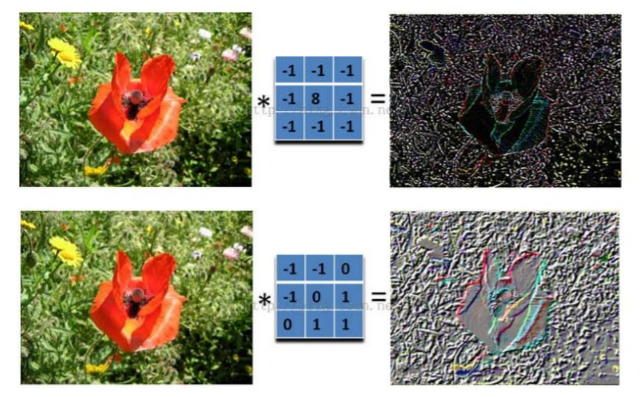
在下图对应的计算过程中,输入是一定区域大小(width*height)的数据,和滤波器filter(带着一组固定权重的神经元)做内积后等到新的二维数据。
具体来说,左边是图像输入,中间部分就是滤波器filter(带着一组固定权重的神经元),不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。
如下图所示
4.4 GIF动态卷积图
在CNN中,滤波器filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。这个过程中,有这么几个参数:
a. 深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数。
b. 步长stride:决定滑动多少步可以到边缘。
c. 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。
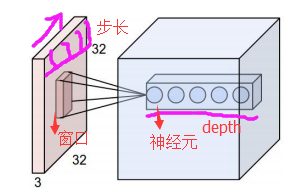
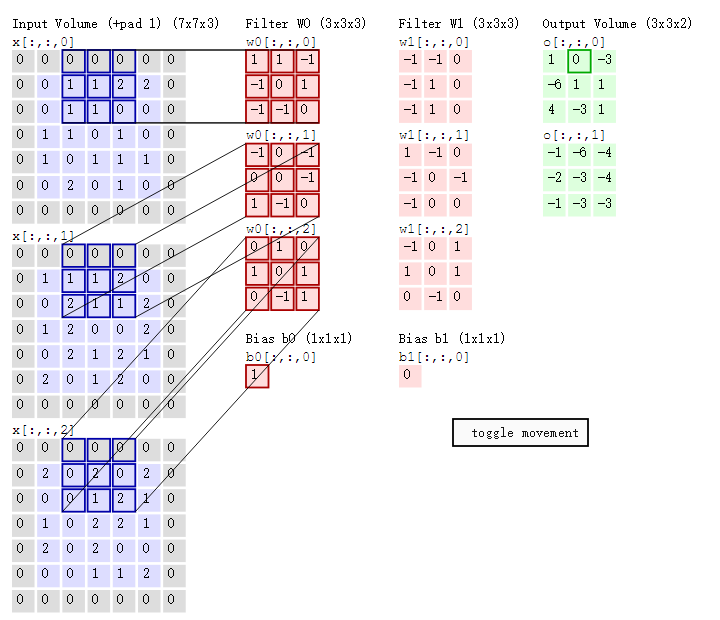
cs231n课程中有一张卷积动图,貌似是用d3js 和一个util 画的,我根据cs231n的卷积动图依次截取了18张图,然后用一gif 制图工具制作了一gif 动态卷积图。如下gif 图所示
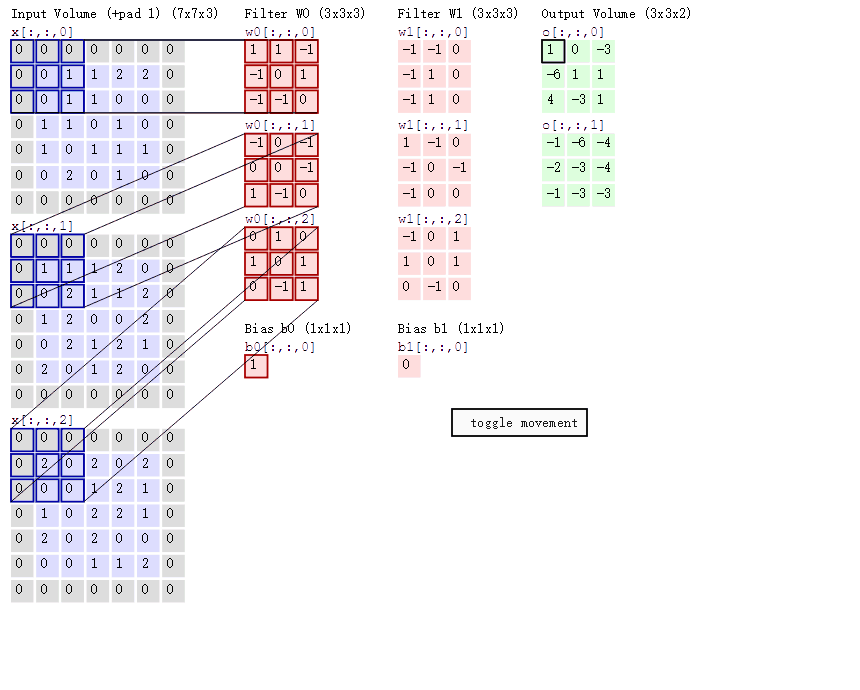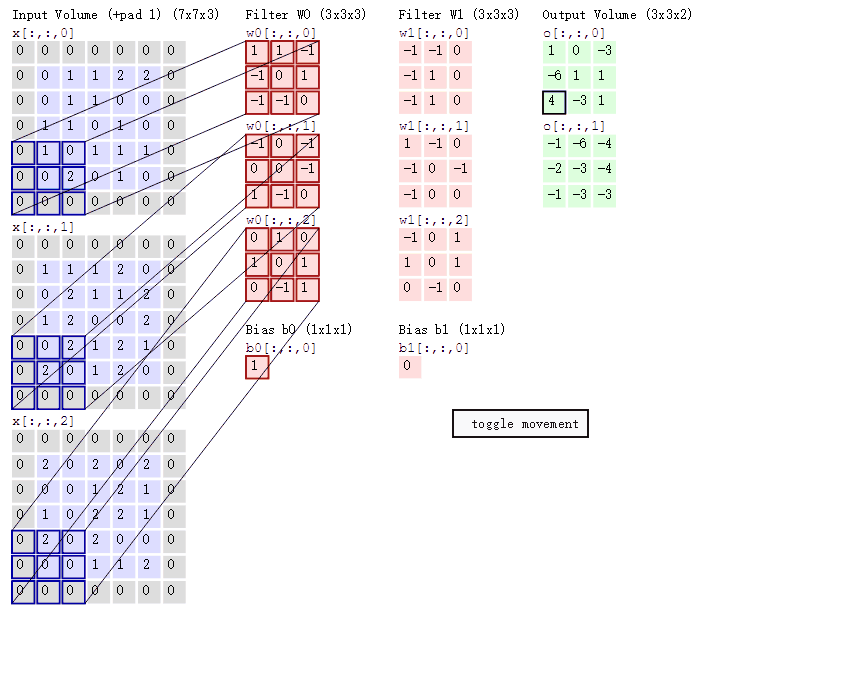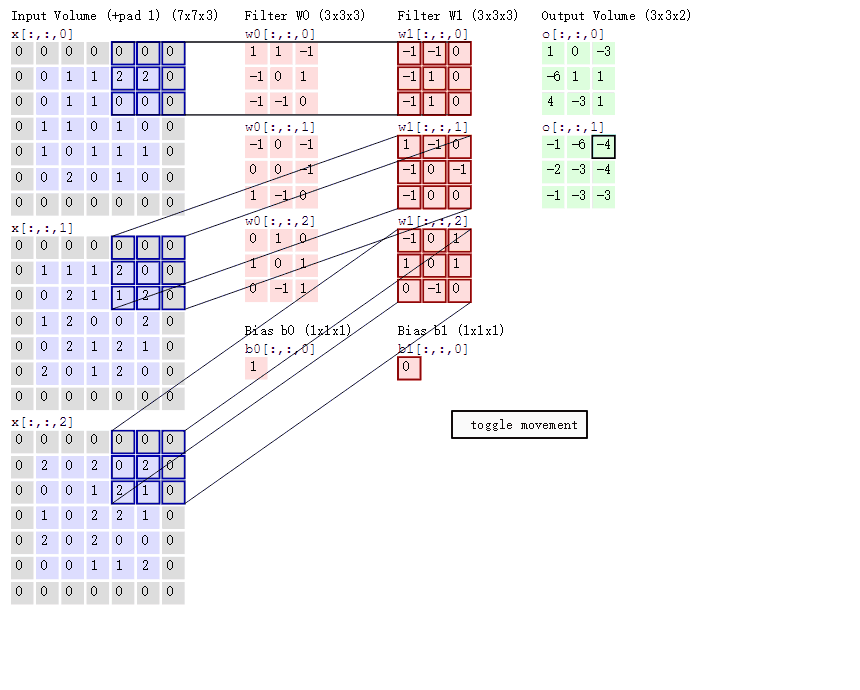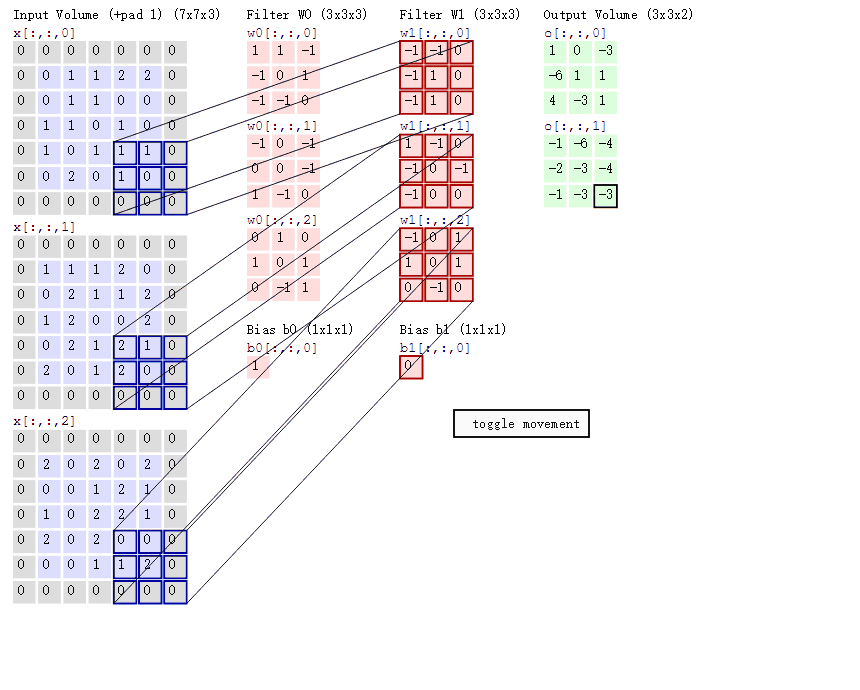
可以看到:
- 两个神经元,即depth=2,意味着有两个滤波器。
- 数据窗口每次移动两个步长取3*3的局部数据,即stride=2。
- zero-padding=1。
然后分别以两个滤波器filter为轴滑动数组进行卷积计算,得到两组不同的结果。
如果初看上图,可能不一定能立马理解啥意思,但结合上文的内容后,理解这个动图已经不是很困难的事情:
- 左边是输入(773中,7*7代表图像的像素/长宽,3代表R、G、B 三个颜色通道)
- 中间部分是两个不同的滤波器Filter w0、Filter w1
- 最右边则是两个不同的输出
随着左边数据窗口的平移滑动,滤波器Filter w0 / Filter w1对不同的局部数据进行卷积计算。
值得一提的是:左边数据在变化,每次滤波器都是针对某一局部的数据窗口进行卷积,这就是所谓的CNN中的局部感知机制。
- 打个比方,滤波器就像一双眼睛,人类视角有限,一眼望去,只能看到这世界的局部。如果一眼就看到全世界,你会累死,而且一下子接受全世界所有信息,你大脑接收不过来。当然,即便是看局部,针对局部里的信息人类双眼也是有偏重、偏好的。比如看美女,对脸、胸、腿是重点关注,所以这3个输入的权重相对较大。
与此同时,数据窗口滑动,导致输入在变化,但中间滤波器Filter w0的权重(即每个神经元连接数据窗口的权重)是固定不变的,这个权重不变即所谓的CNN中的参数(权重)共享机制。
- 再打个比方,某人环游全世界,所看到的信息在变,但采集信息的双眼不变。btw,不同人的双眼 看同一个局部信息 所感受到的不同,即一千个读者有一千个哈姆雷特,所以不同的滤波器 就像不同的双眼,不同的人有着不同的反馈结果。
我第一次看到上面这个动态图的时候,只觉得很炫,另外就是据说计算过程是“相乘后相加”,但到底具体是个怎么相乘后相加的计算过程 则无法一眼看出,网上也没有一目了然的计算过程。本文来细究下。
首先,我们来分解下上述动图,如下图
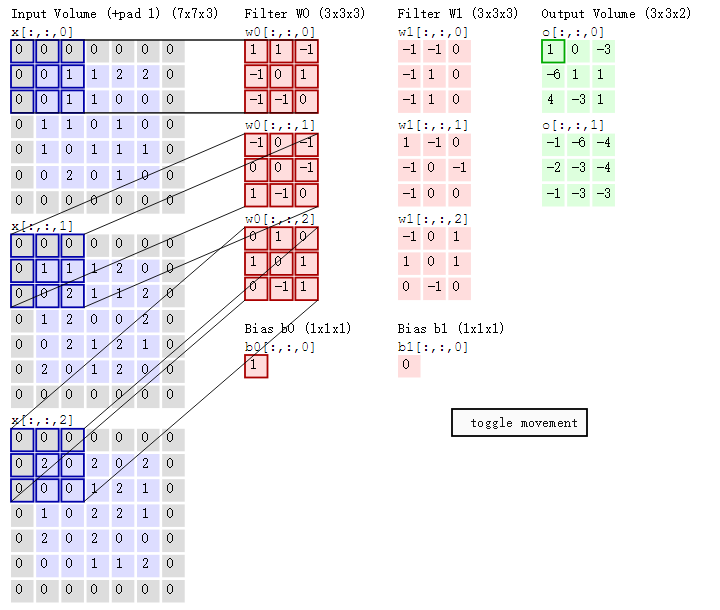
接着,我们细究下上图的具体计算过程。即上图中的输出结果1具体是怎么计算得到的呢?其实,类似wx + b,w对应滤波器Filter w0,x对应不同的数据窗口,b对应Bias b0,相当于滤波器Filter w0与一个个数据窗口相乘再求和后,最后加上Bias b0得到输出结果1,如下过程所示:
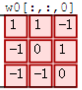

1* 0 + 10 + -10
-10 + 00 + 1*1
-10 + -10 + 0*1

-10 + 00 + -1*0
00 + 01 + -1*1
10 + -10 + 0*2
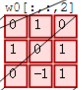
00 + 10 + 0*0
10 + 02 + 1*0
00 + -10 +1*0
1
=
1
然后滤波器Filter w0固定不变,数据窗口向右移动2步,继续做内积计算,得到0的输出结果
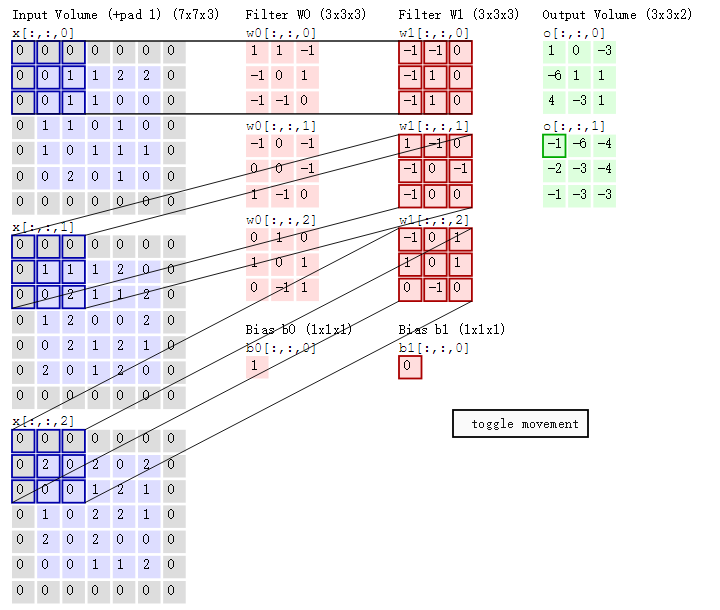
最后,换做另外一个不同的滤波器Filter w1、不同的偏置Bias b1,再跟图中最左边的数据窗口做卷积,可得到另外一个不同的输出。
5 CNN之激励层与池化层
5.1 ReLU激励层
2.2节介绍了激活函数sigmoid,但实际梯度下降中,sigmoid容易饱和、造成终止梯度传递,且没有0中心化。咋办呢,可以尝试另外一个激活函数:ReLU,其图形表示如下
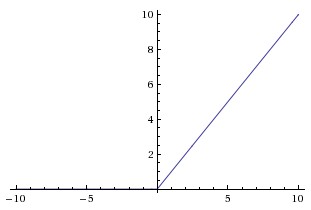
ReLU的优点是收敛快,求梯度简单。
5.2 池化pool层
前头说了,池化,简言之,即取区域平均或最大,如下图所示(图引自cs231n)
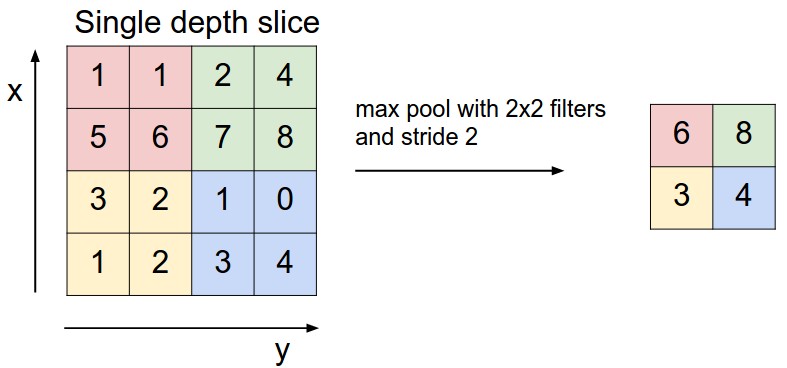
上图所展示的是取区域最大,即上图左边部分中 左上角2x2的矩阵中6最大,右上角2x2的矩阵中8最大,左下角2x2的矩阵中3最大,右下角2x2的矩阵中4最大,所以得到上图右边部分的结果:6 8 3 4。很简单不是?
6 参考文献及推荐阅读
- 人工神经网络wikipedia
- 斯坦福机器学习公开课
- Neural networks and deep learning
- 雨石 卷积神经网络:卷积神经网络_雨石-CSDN博客_卷积神经网络
- cs231n 神经网络结构与神经元激励函数:CS231n Convolutional Neural Networks for Visual Recognition,中译版
- cs231n 卷积神经网络:CS231n Convolutional Neural Networks for Visual Recognition
- 七月在线寒老师讲的5月dl班第4次课CNN与常用框架视频,已经剪切部分放在七月在线官网:julyedu.com
- 七月在线5月深度学习班第5课CNN训练注意事项部分视频:视频播放
- 七月在线5月深度学习班:5 月深度学习班 [国内第1个DL商业课程] - 七月在线
- 七月在线5月深度学习班课程笔记——No.4《CNN与常用框架》:CNN与常用框架_会思考的蜗牛-CSDN博客_cnn框架
- 七月在线6月数据数据挖掘班第7课视频:数据分类与排序
- 手把手入门神经网络系列(1)_从初等数学的角度初探神经网络:手把手入门神经网络系列(1)_从初等数学的角度初探神经网络
- 深度学习与计算机视觉系列(6)_神经网络结构与神经元激励函数:深度学习与计算机视觉系列(6)_神经网络结构与神经元激励函数
- 深度学习与计算机视觉系列(10)_细说卷积神经网络:深度学习与计算机视觉系列(10)_细说卷积神经网络
- zxy 图像卷积与滤波的一些知识点:图像卷积与滤波的一些知识点_zouxy09的专栏-CSDN博客_图像卷积
- zxy 深度学习CNN笔记:Deep Learning(深度学习)学习笔记整理系列之(七)_zouxy09的专栏-CSDN博客_深度学习 笔记
- Understanding Convolutional Neural Networks for NLP – WildML,中译版
- 《神经网络与深度学习》中文讲义:Sina Visitor System
- ReLU与sigmoid/tanh的区别:请问人工神经网络中的activation function的作用具体是什么?为什么ReLu要好过于tanh和sigmoid function? - 知乎
- CNN、RNN、DNN内部网络结构区别:CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别? - 知乎
- 理解卷积:如何通俗易懂地解释卷积? - 知乎
- 神经网络与深度学习简史:1 感知机和BP算法、4 深度学习的伟大复兴
- 在线制作gif 动图:在线Photoshop 在线ps
- 支持向量机通俗导论(理解SVM的三层境界)
- CNN究竟是怎样一步一步工作的? 本博客把卷积操作具体怎么个计算过程写清楚了,但这篇把为何要卷积操作也写清楚了,而且配偶图非常形象,甚赞。
7 后记
本文基本上边看5月dl班寒讲的CNN视频边做笔记,之前断断续续看过不少CNN相关的资料(包括cs231n),但看过视频之后,才系统了解CNN到底是个什么东西,作为听众 寒讲的真心赞、清晰。然后在写CNN相关的东西时,发现一些前置知识(比如神经元、多层神经网络等也需要介绍下),包括CNN的其它层次机构(比如激励层),所以本文本只想简要介绍下卷积操作的,但考虑到知识之间的前后关联,所以越写越长,便成本文了。
此外,在写作本文的过程中,请教了我们讲师团队里的寒、冯两位,感谢他两。同时,感谢爱可可老师的微博转发,感谢七月在线所有同事。
以下是修改日志:
- 2016年7月5日,修正了一些笔误、错误,以让全文更通俗、更精准。有任何问题或槽点,欢迎随时指出。
- 2016年7月7日,第二轮修改完毕。且根据cs231n的卷积动图依次截取了18张图,然后用制图工具制作了一gif 动态卷积图,放在文中4.3节。
- 2016年7月16日,完成第三轮修改。本轮修改主要体现在sigmoid函数的说明上,通过举例和统一相关符号让其含义更一目了然、更清晰。
- 2016年8月15日,完成第四轮修改,增补相关细节。比如补充4.3节GIF动态卷积图中输入部分的解释,即773的含义(其中7*7代表图像的像素/长宽,3代表R、G、B 三个颜色通道)。不断更易懂。
- 2016年8月22日,完成第五轮修改。本轮修改主要加强滤波器的解释,及引入CNN中滤波器的通俗比喻。
July、最后修改于二零一六年八月二十二日中午于七月在线办公室。
版权说明 : 本文为转载文章, 版权归原作者所有 版权申明
原文链接 : https://blog.csdn.net/v_JULY_v/article/details/51812459
内容来源于网络,如有侵权,请联系作者删除!