我试图选择一个按状态分组的计数的最大值(因此状态中每个不同的值有一个最大值)。count函数按预期工作。
SELECT c.id, c.name, t.name as type, COUNT(*) as count, c.state
FROM bookings_facilities f
JOIN bookings b
ON b.id = f.booking_id
JOIN clients c
ON c.id = b.client_id
JOIN client_types t
ON c.type = t.id
WHERE t.name = "School"
GROUP BY c.id这是结果,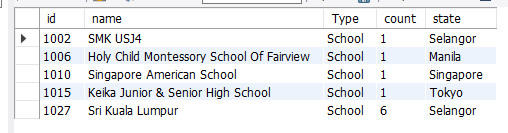
我使用下面的sql语句尝试选择按状态分组的最大计数。
SELECT *, MAX(z.count)
FROM (SELECT c.id, c.name, t.name as type, COUNT(*) as count, c.state
FROM bookings_facilities f
JOIN bookings b
ON b.id = f.booking_id
JOIN clients c
ON c.id = b.client_id
JOIN client_types t
ON c.type = t.id
WHERE t.name = "School"
GROUP BY c.id) z
GROUP BY z.state这是结果,
三种状态,每种状态只出现一次 result 1 看起来不错,但对国家来说, Selangor 在第一个结果中出现两次的出现了一些问题。
sql查询选择了正确的最大值(count),即6,但它没有将id返回为1027,而是将id返回为1002,在第一个结果中,count仅为1。
我尝试了不同的数据集,但我似乎无法获得实际的max(count)行的详细信息。
以下是数据库设计参考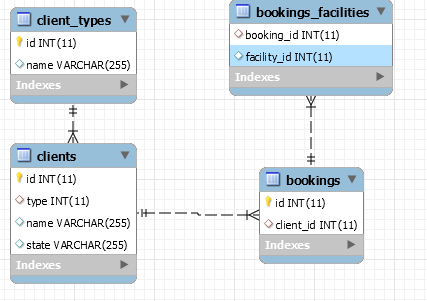
sql小提琴
预期结果是这样的(只需要更改第二行输出)。
电流输出环节
1条答案
按热度按时间c8ib6hqw1#
既然您可以使用mysql 8.0,我们就可以使用窗口函数来解决您的问题。在一个
state,我们将确定Row_Number()具有最高计数的行作为行号1,依此类推。现在,我们只需要考虑那些行号为1的行,对于一个特定的state.另外,在你的尝试中,
GROUP BY不是有效的sql。mysql的旧版本是宽容的,允许使用它;但新版本不会,除非你关闭严格的only_full_group_by模式。但是,不应禁用它,而应修复查询。基本要点是,当使用Group By,您的Select子句只能包含聚合列/表达式和/或中定义的列/表达式Group By条款。do read:在mysql中执行查询时,只与\u full \u group \u by相关的错误结果:
db fiddle视图